今日ちょっと雑に、Mastodon管理者向けにチェック項目をなげたのですが、投げっぱなしもなんなので、説明つけときます。
- Mastodon保守メモ 移転!!
- ディスク空き容量は大丈夫?
- 証明書の期限は大丈夫?
- バックアップ……ちゃんと動いてる?
- サーバからのメールちゃんと届く?
- schedulerキュー動いてる?
- ストリーミング死んでない?
- WebUI生きてる?
- /api/v1/instance 動いてる?
- ca-certificates更新してある?
- サーバ代払い忘れてない? ドメイン代払い忘れてない? クレカの期限大丈夫?
- なぜかリアクションない人いない? 最近みかけなくなったサーバない?
- なんか最近サーバの反応遅くない?
- 新規登録の承認忘れてない? スパム生えてない? 通報対応忘れてない?
- 箇条書きのサーバーのルール書いた?
- OSのパッケージ更新してる?
- Mastodonの更新してる?
Mastodon保守メモ 移転!!
Mastodon管理者必見の記事だよ。 場所が移ってるので、みんなブックマークし直しとこうね!!
ブックマークしたね??
では、続きを……。
ディスク空き容量は大丈夫?
たまにストレージ空き容量を確認してください。
サーバトラブルのかなりの割合が、最終的にディスクフル(空き容量がなくなっている)だったりします。
正常時はこのぐらい、という数値を覚えてないと異常に気付きにくいです。 でも使用率が99%とか100%になってたらもちろんダメです。
ストレージ全体
とりあえず df -h だけは覚えておいて。
noel@mastodon:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 941M 0 941M 0% /dev tmpfs 199M 1.2M 197M 1% /run /dev/vda1 25G 17G 7.2G 70% / tmpfs 991M 3.6M 987M 1% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 991M 0 991M 0% /sys/fs/cgroup /dev/loop0 55M 55M 0 100% /snap/core18/1705 /dev/loop2 241M 241M 0 100% /snap/gnome-3-34-1804/24 /dev/loop1 56M 56M 0 100% /snap/core18/1885 /dev/loop3 256M 256M 0 100% /snap/gnome-3-34-1804/36 /dev/loop5 63M 63M 0 100% /snap/gtk-common-themes/1506 /dev/loop4 50M 50M 0 100% /snap/snap-store/433 /dev/loop6 30M 30M 0 100% /snap/snapd/8790 /dev/loop7 50M 50M 0 100% /snap/snap-store/467 /dev/loop8 28M 28M 0 100% /snap/snapd/7264 tmpfs 199M 0 199M 0% /run/user/1002
7.2GBあいてる! ヨシ!
PostgreSQL
データベース(PostgreSQL)をみて、base、pg_walあたりを確認。
walバックアップとかレプリケーションがらみでpg_walが肥大してディスクフルになるパターン、結構あります。 復旧もわりと大変です。ちゃんとやらないと壊すので……。
たまに、pg_dumpして吐き出したバックアップが置いてあって、やたら容量を食っている場合があります。 同じディスク上に置いてあっても、オペレーションミスのリカバリ(それはそれで重要ですが)ぐらいにしか使えないので、用が済んだら削除したり、別の場所に移動してください。
データベースを小さく保つTIPSは、ここに書き切れないので別記事にします。
noel@mastodon:~$ sudo -u postgres du -h -d1 /var/lib/postgresql/14/main 4.0K /var/lib/postgresql/14/main/pg_replslot 4.0K /var/lib/postgresql/14/main/pg_tblspc 296K /var/lib/postgresql/14/main/pg_stat_tmp 176K /var/lib/postgresql/14/main/pg_subtrans 241M /var/lib/postgresql/14/main/pg_wal 6.7G /var/lib/postgresql/14/main/base 4.0K /var/lib/postgresql/14/main/pg_stat 4.0K /var/lib/postgresql/14/main/pg_dynshmem 4.0K /var/lib/postgresql/14/main/pg_serial 576K /var/lib/postgresql/14/main/global 1.5M /var/lib/postgresql/14/main/pg_xact 16K /var/lib/postgresql/14/main/pg_logical 4.0K /var/lib/postgresql/14/main/pg_snapshots 4.0K /var/lib/postgresql/14/main/pg_notify 4.0K /var/lib/postgresql/14/main/pg_commit_ts 28K /var/lib/postgresql/14/main/pg_multixact 4.0K /var/lib/postgresql/14/main/pg_twophase 6.9G /var/lib/postgresql/14/main
ログ
これはログ。適切に設定してあればそんなに肥大しませんが、容量の少ない場合は節約する設定をしましょう。
noel@mastodon:~$ sudo du -h -d1 /var/log 424K /var/log/letsencrypt 4.0K /var/log/sysstat 206M /var/log/journal 4.0K /var/log/cups 4.0K /var/log/private 120K /var/log/postgresql 92K /var/log/unattended-upgrades 4.0K /var/log/dist-upgrade 4.0K /var/log/installer 40K /var/log/mastodon 600K /var/log/redis 35M /var/log/nginx 112K /var/log/apt 609M /var/log
たとえば、journaldが保持するログを200MBぐらいに制限するなら、例えばこう(よく調べてね)。
sudo sed -i 's/#*SystemMaxUse=.*/SystemMaxUse=200M/g' /etc/systemd/journald.conf sudo systemctl restart systemd-journald
Mastodon
これはMastodonのディレクトリ。
この例では、yarnのキャッシュを削除してありますが、意外とでかいので注意。yarn cache clean
.rbenvが大きいことがあります。rubyのアップデートをして、前のバージョンが残ってるとか。
rbenv versionsして、使ってないのあったらrbenv uninstall 2.6.6とか。
noel@mastodon:~$ sudo -u mastodon du -h -d1 /home/mastodon/ 115M /home/mastodon/.rbenv 24K /home/mastodon/.gem 8.0K /home/mastodon/.yarn 12K /home/mastodon/.local 21M /home/mastodon/.bundle 12K /home/mastodon/.cache 785M /home/mastodon/live 919M /home/mastodon/
こっちはliveの中身。 オブジェクトストレージを使っていない場合は、publicがどんどん大きくなります。
空き容量が本気でヤバイ時は、Mastodonとめて、node_modulesとvendorディレクトリを削除していいです。あとでbundle installやyarn installすれば復活します。トラブル時にも有効だよ!
noel@mastodon:~$ sudo -u mastodon du -h -d1 /home/mastodon/live/ 36K /home/mastodon/live/streaming 16K /home/mastodon/live/nanobox 4.0K /home/mastodon/live/log 48K /home/mastodon/live/.github 1.4M /home/mastodon/live/db 6.9M /home/mastodon/live/tmp 326M /home/mastodon/live/node_modules 214M /home/mastodon/live/vendor 7.3M /home/mastodon/live/config 68M /home/mastodon/live/public 12K /home/mastodon/live/.circleci 8.0K /home/mastodon/live/.bundle 20K /home/mastodon/live/dist 23M /home/mastodon/live/app 52K /home/mastodon/live/bin 784K /home/mastodon/live/build 134M /home/mastodon/live/.git 4.5M /home/mastodon/live/spec 116K /home/mastodon/live/chart 472K /home/mastodon/live/lib 785M /home/mastodon/live/
証明書の期限は大丈夫?
主にLet's Encryptを使っている場合の話ですが、期限が発行から3か月なので、更新に失敗して期限切れ、非常によく発生します。
cronなりsystemd timerなりで、certbot renewが実行されているか、nginxがreloadされているか、確認が必要です。 ここではsystemd timerで更新する前提とし、設定例も記載しておきます。
systemd timerでcertbot renew
- systemdのtimerを利用し、毎日2回certbot renewを実行させる
- renewは、有効期限が1か月を切るまで何もしないので、定期実行して良い
- 実行時間を散らすために43200秒以内の乱数を加える
- cronとの違いとして、たまたま実行予定だったタイミングでダウンしていても、復帰時に実行してくれる、予定を一覧できる、実行結果を確認しやすい、などがある
sudo systemctl edit --full --force certbot-renewal
エディタが開くので、下記の内容をペーストする
[Unit] Description=Certbot Renewal [Service] Type=oneshot ExecStart=/usr/local/bin/certbot -q renew PrivateTmp=true
sudo -e /etc/systemd/system/certbot-renewal.timer
エディタが開くので、下記の内容をペーストする
[Unit] Description=Run certbot-renewal twice daily [Timer] OnCalendar=*-*-* 00,12:00:00 RandomizedDelaySec=43200 Persistent=true [Install] WantedBy=timers.target
有効にして開始
sudo systemctl enable certbot-renewal.timer sudo systemctl start certbot-renewal.timer
証明書の確認
certbot
期限切れになっていないか、期限が近いのに未更新になっていないか(定期更新の失敗)確認する。
sudo certbot certificates
nginx
curlを使い、webサーバ(nginx)から証明書の期限を確認する。これは、証明書の更新はしていたが、nginxのプロセス再起動するのを忘れた・失敗した、というケースに対応するため。
なお、CloudflareなどのCDNを介している場合、普通にURL指定するとCloudflareの証明書をチェックしにいってしまうため、Webサーバ上(ネットワーク内部)でcurlを実行し、curlの機能を使って内部のnginxに直接アクセスさせてチェックを行う。(example.comを運営するドメインに変更して実行すること)
curl -v --resolve example.com:443:127.0.0.1 https://example.com/ 3> /dev/null 2>&1 1>&3 | grep 'expire date:'
定期実行タスクの確認
現在仕掛けられているタイマーの一覧から、次の実行日時(NEXT)、実行までの時間(LEFT)、最終実行日時(LAST)、実行後の経過時間(PASSED)をチェックする。
sudo systemctl list-timers
以下はコマンドの実行結果の抜粋。
NEXT LEFT LAST PASSED UNIT ACTIVATES Mon 2022-01-17 14:39:49 JST 1h 19min left Mon 2022-01-17 00:09:31 JST 13h ago certbot-renewal.timer certbot-renewal.service
また、実行結果のログを確認して、正常実行されているか(エラーがでていないか)確認する。
sudo journalctl -ru certbot-renewal
バックアップ……ちゃんと動いてる?
はい。案外、ちゃんと動いてません! 身近なデータベース喪失事件、記憶に新しいですね??
バックアップ先のファイルの日付とかサイズをみて異常ないことをざっと見るだけでも違います。 バックアップの実行ログもみます。 ときには、無意味なバックアップをとっていることもあります。中身が切り替え前のデータだったとか!
できれば、バックアップからの復旧作業を実際にやるべきです。 手順になれておけば、いざという時に、手際よく復旧作業が可能です。
また、何度もやると、自然に作業手順が明確に洗練され、手順書を残して人に託せるようになります。 これは管理者のバックアップみたいなものです。
どのデータをバックアップすればいいか……まあこういうのは公式ドキュメントを読んだ方がいいですね。 docs.joinmastodon.org
サーバからのメールちゃんと届く?
sendmail / postfix自前設置というパターンは少ないと思いますが、スパム鯖扱いされやすいです。世知辛い……。
MailgunなりSendGrid、Amazon SES、Gmailっていうのもあるかな。 DNSへの設定など、推奨される設定をちゃんとやる。これは説明しきれないので、できているものとします。
問題は、実際にちゃんと届くか。
これが動いていないと、新規登録ユーザーが登録完了できないのはもちろんですが、二段階認証を設定していないユーザー(特に久しぶりにログインしたり、いつもと違う端末からログインする場合)にメールで確認コードが送られ、それを入力する必要があるため、ログインできなくなってハマったりします。面倒くさくなってアカウントを放棄してしまう人もいます。
送信テストしましょう。
RAILS_ENV=production bin/rails runner "UserMailer.new.mail(to:'admin@example.com', subject: 'test', body: 'awoo').deliver"
mastodonユーザーでログインし、liveディレクトリで、rails runnerを使ってメールを飛ばします。
admin@example.comのところを、自分のメールアドレスなど、いくつか違うメールサーバのアドレスに変えて試してください。
schedulerキュー動いてる?
v3.3以降、以前まで存在しなかったschedulerキューという新しいキューが増えています。
古いサーバ設定で、sidekiqのキューを直接指定してある場合に、schedulerキューが指定されていないために、Mastodonの定期タスクがまったく実行されなくなっている場合があります。最新のMastodonでは、管理画面のダッシュボードに警告がでるようになっています。
sidekiqを複数プロセス実行するカスタマイズをしていない場合は、単純にキューの指定を削除すると良いです。 複数プロセス走らせている場合、そのうちのひとつだけでschedulerキューを実行させます。
リリースノートを参照してください。 github.com
設定例は、この変更のプルリクエストを参照してください。 github.com
ストリーミング死んでない?
ストリーミングは、WebUIやクライアントアプリに対し、新しい投稿や削除を知らせたり、通知やお知らせなどをリアルタイムに伝達する役割を果たしています。きちんと動作しているかどうか、時々気にしておいてください。
ストリーミングが止まっている場合でも、定期的に新しい投稿がないかAPIで確認したり(ポーリング)、ブラウザやクライアントでリロードすることで読み直すことはできますが、非常に不便です。不便ですが、使えないことはないので、メンテナンスの悪いサーバでは、不具合がおきたまま放置されることもあります。
WebUI生きてる?
クライアントアプリではアクセスできるが、ブラウザから見に行くとエラー画面が出るパターンがあります。APIは生きているけど、WebUIだけが死んでいるパターンです。
assets:precompileに失敗していて、JavaScriptの実行コードがブラウザにちゃんと渡せていないことがほとんどです。
管理者がクライアントアプリ中心で使っていると気付かない・気付くのが遅れるパターンがあるので、ブラウザでもチェックするようにするといいです。まぁ、基本的にアップデートしたときに発生する不具合なので、自分で壊して放置しないように、アップデート後にしっかり確認しておきましょう、という話ですね!
/api/v1/instance 動いてる?
サーバの基本的な情報を取得するためのAPIですが、これがエラーになるケースがあります。 このAPIが動いていないと、MastodonとPleroma両対応のクライアントアプリでサーバが認識できなくなったり(SubwayTooterなど)、様々な不具合が発生します。
最近のMastodonで、マテリアライズドビューという、計算済みのデータを保持する特殊なビューを使うようになっているのですが、計算済みのデータがあることを前提としているため、これが準備されていないと動きません。ここで問題になるのはinstancesというビューなので、初期化し損なっている場合はデータベースにrefresh materialized view instancesというSQLを実行させればOKです。
sudo -u postgres psql -d mastodon_production -c 'refresh materialized view instances'
ca-certificates更新してある?
システムにインストールされているルート証明書の一覧を更新しないと、新しい証明書が正規のものと認識できなくなる問題があります。
Let's Encryptを証明書に使っているMastodonサーバ(あるいはPleromaやMisskeyなどActivityPubのサーバ)はたくさんありますが、自分のサーバから相手のサーバへのアクセスの際に、この証明書を信頼できずアクセス不能になる問題が発生します。この問題そのものの説明は割愛します。まあこのへんみて。
ActivityPubはサーバ同士が相互に相手へアクセスするので、片方だけ成功しても、もう片方が失敗すると、やりとりができなくなります。自分のサーバの証明書については完璧に管理できていても、相手の証明書をチェックするためのデータベースが古くなっていることで、失敗してしまうのです。
Ubuntu / Debianなら apt install ca-certificates、CentOSなら yum -y update ca-certificates、CentOS 6以前だとOpenSSLが古すぎてつらいので、OSごと変えた方がいいかな……。
サーバ代払い忘れてない? ドメイン代払い忘れてない? クレカの期限大丈夫?
サーバダウンの原因、代金未払い、実は凄くあります……つらい。クレジットカードの期限切れも罠です。払えよ! ちゃんと払えよ、絶対だぞ!
ドメインの更新にしくじって、そのドメインを失ってしまい、サーバ閉鎖に至った事例もあります。つらい。
なぜかリアクションない人いない? 最近みかけなくなったサーバない?
いつもお気に入りとかリプライくれるのに、なんかスルーされてる? 反応少ない? とか、そういやあの人どこいったんだろう? 最近人が少なくなったな……。
ブロックされてる場合ももちろんありますが、サーバ同士の通信がうまくいってないだけかもしれません!! 前項のca-certificatesが原因の場合もありますが、とにかく、おかしいなと思ったら調べてみてください。
なんか最近サーバの反応遅くない?
起動しっぱなしで、メモリ使用量が肥大してスワップ大動員になっててパフォーマンス落ちてるなどは、サーバの再起動でだいたいなおります。
再起動する前に、freeやtopなどでざっくりメモリの使用状況をみておいてください。
あと、ブラウザのDevToolsなどで、APIコールの応答時間などを見ておきます。あるいは、サーバのmastodon-webプロセスのログを見ます。著しく速度低下していたり、一部の速度が極端に落ちていたら、データベースに問題がある場合があります。通常時の速度を承知していないと、遅くなっているのか判断付きにくいですが、体感で遅いなと思うぐらいであれば一桁以上遅くなっているので、まあ分かります。
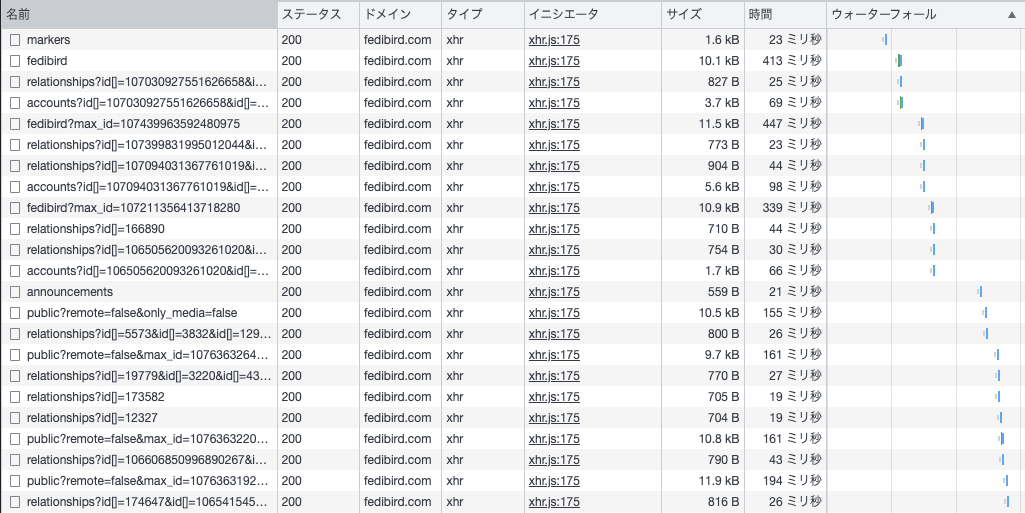
データベースの速度低下は、重複レコードの発生、インデックスそのものが壊れている、統計情報が実情と乖離し実行計画がおかしくなっているなどで多くみられます。
重複レコードはヤバイので、tootctl maintenanceなどで対処します。これみて!
インデックスの作り直しは、reindex インデックス名などでいけるんですが、pg_repackの利用をおすすめします。
統計情報は意外と重要な要素です。
データベースはアプリケーションから指示されたSQLを実行する際に、どうやったら一番効率良く実行できるか計画を立ててから、その計画に従って具体的な処理を行います。この時、データ少ないからメモリの中で処理しきれるこのソートアルゴリズム使おうとか、こりゃインデックス使うより順番にみた方が早いやとか、状況に応じた賢い判断をしています。……ただし、状況判断が間違っていると、とんでもない非効率な処理を選択することがあります。
統計情報はANALYZEというSQLでさくっと再計算させられるので、これ、実行時間がおかしいな? と思ったら一回やってみましょう。
すごく乱暴にやるなら、こうです。
sudo -u postgres psql -d mastodon_production -c 'analyze'
新規登録の承認忘れてない? スパム生えてない? 通報対応忘れてない?
あんまりほったらかしにしておくと……いつの間にかリモートサーバが問題の対処に頭を抱えていて、やむなくブロックということも。
まあ、この記事を読んでいる人が該当するわけがないので、この項目は意味がないですね!!
箇条書きのサーバーのルール書いた?
比較的新しいMastodonの機能で、サーバのルールの箇条書き設定が増えています。 これは、MastodonのiOS用公式アプリにあわせて作られた、新規ユーザーに読ませたい項目を、フォーマット統一して見せるためのもの。
従来のページももちろん有効ですが、スマートフォンのような狭い画面で、ちゃんと把握しておいて欲しい最低限のルールを提示しようというものです。未設定だとダッシュボードに警告が出ます。ま、なんか設定しておきましょうね。
OSのパッケージ更新してる?
Ubuntu / Debianならapt、CentOSならyumなど、ディストリビューションのパッケージでセキュリティ修正などが頻繁に配布されています。内容をよく確認して、といいたいところですが、皆が皆、内容を理解できるわけでもありません。ディストリビューションのメンテナがそれなりに確認してくれていることを信じて、ともかくあてておく、という対応が現実的かと思います。
特定のサービスを再起動するものもありますし、OS全体の再起動が必要になる修正もありますので、実行するタイミングだけ良く考えて、メンテナンス時間をとるようにしてくだささい。
Mastodonの更新してる?
一次情報としては、MastodonのGithubのリリース一覧ページをみるのが一番良いのですが、
Fediverse、特にMastodonでは、新バージョンがリリースされるとあちこちのサーバ管理者が新バージョンの話をし始めます(通称、鯖缶びちびち)から、このあたりを情報源にしていろんな生の声を拾うのが良いかと思います。何人か生きの良いサーバ管理者をフォローしておきましょうw
OSのセキュリティ修正は、管理者が随時あてていけばいいのですが、Mastodonそのものが使用している様々なコンポーネント、そしてMastodon自身のセキュリティ修正や、バグの修正については、Mastodonのバージョンアップによって行うのが現実的です。
特に、v3.4.1がv3.4.2になるなど0.0.1単位のアップデートは、変更内容は軽微ながら、次のバージョンではなくすぐに直しておいた方がいいと判断されたリリースだったりしますので、速やかに判断してアップデートすることをお勧めします。変更点が絞られているので、問題も起きにくいです。