This is an explanation to the checklist for Mastodon administrators that I posted today.
- Do you have enough free disk space?
- Is the expiration date of the certificate correct?
- Is the backup ...... working properly?
- Does the mail from the server reach you properly?
- Is the scheduler queue working?
- Is streaming working?
- Is the WebUI working?
- Is /api/v1/instance working?
- Are the ca-certificates updated?
- Did you forget to pay the server fee? Did you forget to pay the domain fee? Is your credit card expired?
- Is there anyone who doesn't react for some reason? Are there any servers that you haven't seen recently?
- Is the server responding slowly lately?
- Have you forgotten to approve new registrations? Are there any spam accounts out there? Have you forgotten to report someone?
- Have you written down the "server rules"?
- Have you updated your OS package?
- Have you updated your Mastodon?
Do you have enough free disk space?
Check the free space on your storage from time to time.
Most server problems are caused by the disk becoming full (running out of free space).
If you are not aware of this number on a daily basis, it is hard to notice anything unusual. Of course, if the usage rate goes to 99% or 100%, you are out.
Storage
For now, just remember df -h.
noel@mastodon:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 941M 0 941M 0% /dev tmpfs 199M 1.2M 197M 1% /run /dev/vda1 25G 17G 7.2G 70% / tmpfs 991M 3.6M 987M 1% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 991M 0 991M 0% /sys/fs/cgroup /dev/loop0 55M 55M 0 100% /snap/core18/1705 /dev/loop2 241M 241M 0 100% /snap/gnome-3-34-1804/24 /dev/loop1 56M 56M 0 100% /snap/core18/1885 /dev/loop3 256M 256M 0 100% /snap/gnome-3-34-1804/36 /dev/loop5 63M 63M 0 100% /snap/gtk-common-themes/1506 /dev/loop4 50M 50M 0 100% /snap/snap-store/433 /dev/loop6 30M 30M 0 100% /snap/snapd/8790 /dev/loop7 50M 50M 0 100% /snap/snap-store/467 /dev/loop8 28M 28M 0 100% /snap/snapd/7264 tmpfs 199M 0 199M 0% /run/user/1002
7.2GB free! Good!
PostgreSQL
Look at the database (PostgreSQL) and check base and pg_wal.
There is a pattern that pg_wal is bloated by wal backup and replication and becomes a full disk. It is rather hard to restore. If you don't do it properly, it will break, so check ..........
Sometimes the backups spit out by pg_dump are on the same storage, and they take up a lot of space. Even if it is on the same disk, it can only be used to recover from an operation error (but this is important), so delete it or move it to another location when you are done.
The tips on how to make a database smaller are too long to write here, so I'll leave them for another article.
noel@mastodon:~$ sudo -u postgres du -h -d1 /var/lib/postgresql/14/main 4.0K /var/lib/postgresql/14/main/pg_replslot 4.0K /var/lib/postgresql/14/main/pg_tblspc 296K /var/lib/postgresql/14/main/pg_stat_tmp 176K /var/lib/postgresql/14/main/pg_subtrans 241M /var/lib/postgresql/14/main/pg_wal 6.7G /var/lib/postgresql/14/main/base 4.0K /var/lib/postgresql/14/main/pg_stat 4.0K /var/lib/postgresql/14/main/pg_dynshmem 4.0K /var/lib/postgresql/14/main/pg_serial 576K /var/lib/postgresql/14/main/global 1.5M /var/lib/postgresql/14/main/pg_xact 16K /var/lib/postgresql/14/main/pg_logical 4.0K /var/lib/postgresql/14/main/pg_snapshots 4.0K /var/lib/postgresql/14/main/pg_notify 4.0K /var/lib/postgresql/14/main/pg_commit_ts 28K /var/lib/postgresql/14/main/pg_multixact 4.0K /var/lib/postgresql/14/main/pg_twophase 6.9G /var/lib/postgresql/14/main
Logs
This is the log. If you set it up properly, it won't get so bloated, but if you don't have enough space, you might want to set it up to save space.
noel@mastodon:~$ sudo du -h -d1 /var/log 424K /var/log/letsencrypt 4.0K /var/log/sysstat 206M /var/log/journal 4.0K /var/log/cups 4.0K /var/log/private 120K /var/log/postgresql 92K /var/log/unattended-upgrades 4.0K /var/log/dist-upgrade 4.0K /var/log/installer 40K /var/log/mastodon 600K /var/log/redis 35M /var/log/nginx 112K /var/log/apt 609M /var/log
For example, if you want to limit the logs kept by journald to about 200MB, for example, you can do this (check carefully).
sudo sed -i 's/#*SystemMaxUse=.*/SystemMaxUse=200M/g' /etc/systemd/journald.conf sudo systemctl restart systemd-journald
Mastodon
This is the Mastodon directory.
In this example, we have already deleted the yarn cache. Note that the cache is surprisingly large. To remove it, use yarn cache clean.
.rbenv is large, or you may have updated ruby and still have the previous version.
If you are not using any of them, do rbenv versions and rbenv uninstall 2.6.6.
noel@mastodon:~$ sudo -u mastodon du -h -d1 /home/mastodon/ 115M /home/mastodon/.rbenv 24K /home/mastodon/.gem 8.0K /home/mastodon/.yarn 12K /home/mastodon/.local 21M /home/mastodon/.bundle 12K /home/mastodon/.cache 785M /home/mastodon/live 919M /home/mastodon/
This one is the contents of live. If you are not using object storage, public will get bigger and bigger.
If your free space is seriously limited, you can stop Mastodon and delete the node_modules and vendor directories. You can restore them later with bundle install or yarn install. It's also useful in case of trouble!
noel@mastodon:~$ sudo -u mastodon du -h -d1 /home/mastodon/live/ 36K /home/mastodon/live/streaming 16K /home/mastodon/live/nanobox 4.0K /home/mastodon/live/log 48K /home/mastodon/live/.github 1.4M /home/mastodon/live/db 6.9M /home/mastodon/live/tmp 326M /home/mastodon/live/node_modules 214M /home/mastodon/live/vendor 7.3M /home/mastodon/live/config 68M /home/mastodon/live/public 12K /home/mastodon/live/.circleci 8.0K /home/mastodon/live/.bundle 20K /home/mastodon/live/dist 23M /home/mastodon/live/app 52K /home/mastodon/live/bin 784K /home/mastodon/live/build 134M /home/mastodon/live/.git 4.5M /home/mastodon/live/spec 116K /home/mastodon/live/chart 472K /home/mastodon/live/lib 785M /home/mastodon/live/
Is the expiration date of the certificate correct?
This is mainly when you are using Let's Encrypt, but since the expiration date is 3 months after the issue, it is very common for the renewal to fail and expire.
You need to check if certbot renew is running and nginx is reloaded by cron or systemd timer. Here, we assume that certbot renew is executed by systemd timer, and provide an example of the configuration.
systemd timerでcertbot renew
- Use systemd's timer to run certbot renew twice daily.
- Renew will not do anything until it expires in less than a month, so you can run it periodically.
- To spread out the execution time, add a random number within 43200 seconds.
- The difference between certbot renew and cron is that even if certbot is down when it is supposed to run, it will run when it comes back up, you can list the schedule, and you can easily check the execution result.
sudo systemctl edit --full --force certbot-renewal
When the editor opens, paste the following into it
[Unit] Description=Certbot Renewal [Service] Type=oneshot ExecStart=/usr/local/bin/certbot -q renew PrivateTmp=true
sudo -e /etc/systemd/system/certbot-renewal.timer
When the editor opens, paste the following into it
[Unit] Description=Run certbot-renewal twice daily [Timer] OnCalendar=*-*-* 00,12:00:00 RandomizedDelaySec=43200 Persistent=true [Install] WantedBy=timers.target
Enable and start.
sudo systemctl enable certbot-renewal.timer sudo systemctl start certbot-renewal.timer
Check the certificate.
certbot
Check to see if it has expired, or if it is close to expiring but not yet renewed (failure of periodic renewal).
sudo certbot certificates
nginx
Use curl to check the expiration date of the certificate from the web server (nginx). This is to deal with the case where you have renewed the certificate, but forgot to restart the nginx process or failed to do so.
If you are using a CDN such as Cloudflare, if you specify the URL normally, Cloudflare's certificate will be checked, so run curl on the web server (inside the network) and use the curl function to directly access the internal nginx for checking. This is done by running curl on the web server (inside the network) and using the curl function to directly access the internal nginx. (Change example.com to the domain you want to run on.)
curl -v --resolve example.com:443:127.0.0.1 https://example.com/ 3> /dev/null 2>&1 1>&3 | grep 'expire date:'
Checking Regularly Executed Tasks
From the list of timers currently set up, check the next execution date and time (NEXT), the time until execution (LEFT), the last execution date and time (LAST), and the elapsed time after execution (PASSED).
sudo systemctl list-timers
This is an excerpt of the command execution result.
NEXT LEFT LAST PASSED UNIT ACTIVATES Mon 2022-01-17 14:39:49 JST 1h 19min left Mon 2022-01-17 00:09:31 JST 13h ago certbot-renewal.timer certbot-renewal.service
Also, check the log of the execution results to see if it is running normally (no errors).
sudo journalctl -ru certbot-renewal
Is the backup ...... working properly?
Yes, sir. Surprisingly, it's not working properly! You remember the database loss incident that happened to you, don't you?
Even a quick look at the date and size of the backup destination file will make a difference. Also look at the backup execution log.
Sometimes, you may have made a meaningless backup, and the data inside is the data before the switch!
If possible, you should actually do the restoration from the backup. If you are familiar with the procedure, you will be able to restore the data quickly and easily when the time comes.
Also, if you do it many times, you will naturally be able to refine the procedure clearly and leave a written procedure for others to follow. You could say this is the administrator's own backup!
Which data should be backed up: ...... Well, read the official documentation for this kind of thing! docs.joinmastodon.org
Does the mail from the server reach you properly?
I don't think there are many people who set up their own sendmail / postfix, but it is easy to be treated as a spam mackerel. The world is a hard place. ......
Mailgun, SendGrid, Amazon SES, and Gmail are also options. Make sure you do the recommended settings for DNS. I can't fully explain this, so I'll assume it's done.
The question is, does it actually work?
If this is not working, not only will newly registered users not be able to complete their registration, but also users who have not set up two-step verification (especially if they are logging in after a long time or from a different device than usual) will receive a confirmation code via email and need to enter it. You can't log in and get stuck. Some people even abandon their accounts because it becomes too much of a hassle.
Now, let's test sending it.
RAILS_ENV=production bin/rails runner "UserMailer.new.mail(to:'admin@example.com', subject: 'test', body: 'awoo').deliver".
Log in as the mastodon user, and in the live directory, use the rails runner to send the mail.
Try changing the admin@example.com to your own email address or some other different mail server address.
Is the scheduler queue working?
Since v3.3, there is a new queue called the scheduler queue that did not exist before.
If you have specified the sidekiq queue directly in your old server configuration, Mastodon's scheduled tasks may not be executed at all because the scheduler queue is not specified. In the latest version of Mastodon, you will see a warning on the dashboard of the administration panel.
If you have not customized sidekiq to run multiple processes, you can simply remove the queue specification. If you are running multiple processes, only one of them will run the scheduler queue.
Please refer to the release notes. github.com
For an example configuration, see the pull request for this change. github.com
Is streaming working?
Streaming is responsible for notifying the WebUI and client apps of new posts and deletions, and for communicating notifications and announcements in real time. Please keep an eye on it from time to time to make sure it is working properly.
Even if the streaming is stopped, you can periodically check for new posts via the API (polling) or re-read them by reloading with your browser or client, but it is very inconvenient. It is inconvenient, but not impossible to use, so if the server is poorly maintained, the problem may be left unattended.
Is the WebUI working?
There is a pattern where the client app can access it, but when you go to view it from the browser, you get an error screen.
The API is alive, but only the WebUI is dead.
In most cases, assets:precompile is failing and the JavaScript execution code is not being passed to the browser properly.
If the administrator is using it mainly in the client application, he may not notice or notice it late, so it's a good idea to check it in the browser as well.
Well, basically, this is a bug that occurs when you update, so I'm just saying, make sure you check it thoroughly after the update so you don't break it yourself and leave it!
Is /api/v1/instance working?
This API is used to get basic information about the server, but there are cases where it causes errors. If this API is not working, client applications that support both Mastodon and Pleroma will not be able to recognize the server (SubwayTooter, etc.) and various other problems will occur.
Recently, Mastodon has started to use materialized views, which are special views that hold computed data, but they assume that there is computed data, so they will not work if they are not prepared. The problem here is that the view is called instances, so if you have failed to initialize it, you can run the SQL refresh materialized view instances in the database.
sudo -u postgres psql -d mastodon_production -c 'refresh materialized view instances'
Are the ca-certificates updated?
If you do not update the list of root certificates installed on your system, there is a problem that the new certificates will not be recognized as legitimate.
There are many Mastodon servers (or Pleroma, Misskey, and other ActivityPub servers) that use Let's Encrypt as their certificate, but when you try to access their server from your server, you will encounter a problem where the certificate cannot be trusted and you will lose access. This problem is not explained here. I will not explain the problem itself. See here.
In ActivityPub, servers mutually access each other, so even if one server succeeds, if the other fails, you will not be able to communicate with each other. Even if you have perfect control over your own server's certificate, it will fail because the database used to check the other server's certificate is out of date.
If you are using Ubuntu / Debian, you can apt install ca-certificates, if you are using CentOS, you can yum -y update ca-certificates, if you are using CentOS 6 or earlier, OpenSSL is too old and hard to use, so you might want to change the whole OS. .......
Did you forget to pay the server fee? Did you forget to pay the domain fee? Is your credit card expired?
The cause of server downtime, unpaid bills, is actually very ...... painful. Expired credit cards are also a trap. Pay up! Pay up, I swear!
There have been cases where people have lost their domain names because they failed to renew them, leading to server shutdowns. It's hard.
Is there anyone who doesn't react for some reason? Are there any servers that you haven't seen recently?
I'm always favoriting and replying to you, but I can't get through to you? He's not responding? I don't understand, where is that person? I'm not seeing many people lately.
Of course, it's possible that they are blocked, but it's also possible that the communication between the servers is not going well! The ca-certificates introduced in the previous section may be the cause, but anyway, if you think something is wrong, please check it out.
Is the server responding slowly lately?
If the server has been running for a long time and the memory usage has become too large and swap is being used too much and the performance has dropped, restarting the server will usually fix the problem.
Before rebooting, check the memory usage with free or top.
Also, check the response time of API calls using DevTools in your browser. Or, look at the log of the mastodon-web process on the server. If there is a significant slowdown or some of the speeds are extremely slow, there may be a problem with the database. If you don't know the normal speed, it's hard to tell if it's slowing down, but if it's slowing down by more than an order of magnitude, you can tell.
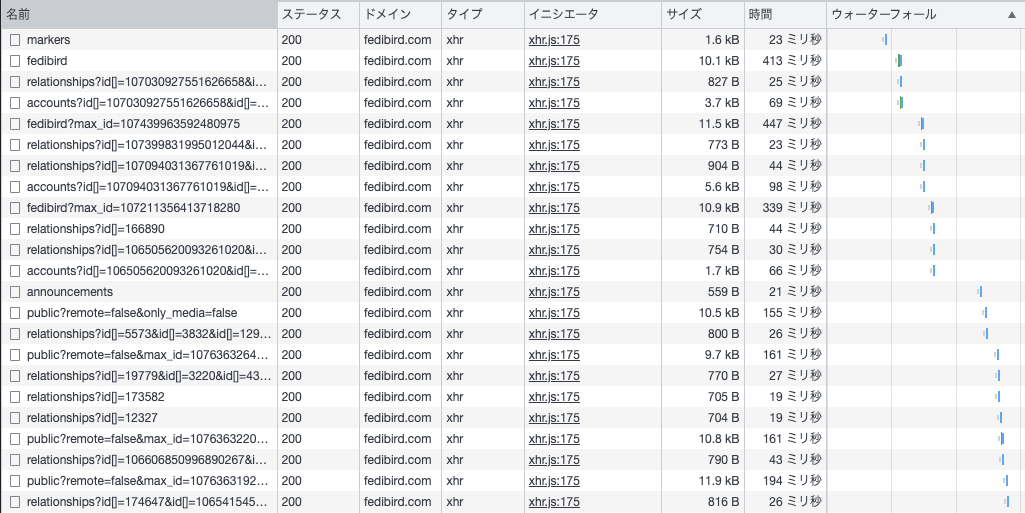
Database slowdowns are often caused by duplicate records, broken indexes, or incorrect execution plans due to deviation of statistics from the actual situation.
Duplicate records are bad, so use tootctl maintenance to deal with them. Look at this!
To reindex, you can use reindex index_name, but we recommend using pg_repack.
Statistics are more important than you might think.
When a database executes SQL, it plans how to execute it most efficiently, and then executes specific processes according to the plan. At this time, it makes a wise decision according to the situation, such as using this sorting algorithm that can be processed in the memory because there is not much data, or that it is faster to look at the data in order than to use an index. ...... However, if the situation is misjudged, it may choose an inefficient process.
Statistics can be quickly recalculated with SQL called ANALYZE, so if you think the execution time is strange, try it. If you think the execution time is wrong, try it once.
If you want to do it very roughly, you can do it like this.
sudo -u postgres psql -d mastodon_production -c 'analyze'
Have you forgotten to approve new registrations? Are there any spam accounts out there? Have you forgotten to report someone?
If you leave it alone for too long, ...... Before you know it, the administrator of the remote server will be so overwhelmed with dealing with the problem that he may be forced to block your server.
Well, it is unlikely that anyone reading this article falls into that category, so this section is pointless!
Have you written down the "server rules"?
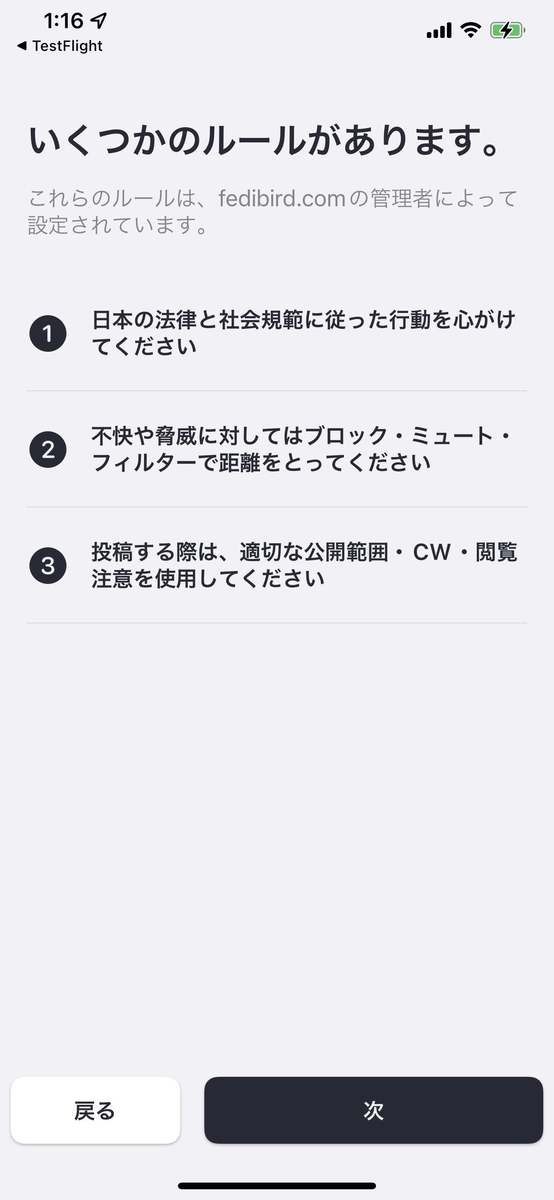
A relatively new Mastodon feature is the growing number of bullet point settings for server rules. This was created in conjunction with Mastodon's official iOS app to show new users the items you want them to read in a unified format.
Of course, the traditional page is still valid, but the idea is to present the minimum rules that we want people to understand properly on a narrow screen like a smartphone. If it is not set, a warning will appear on the dashboard. Well, let's set something up, shall we?
Have you updated your OS package?
Security fixes are frequently distributed in distribution packages such as apt for Ubuntu / Debian, yum for CentOS, and so on.
I would like to say that you should check the contents carefully, but not everyone can understand the contents. I think it is more realistic to trust that the distribution maintainers have checked the contents to a certain extent, and to apply them anyway.
Some fixes may require restarting specific services, and some may require restarting the entire OS, so please think carefully about the timing of the fix and take time for maintenance.
Have you updated your Mastodon?
For primary information, the best place to look is Mastodon's Github release listing page
Whenever a new version of Fediverse, especially Mastodon, is released, server administrators all over the place start talking about the new version (a.k.a. "Sabacan Bichi Bichi"), so I think it's a good idea to use this area as a source of information and pick up various real voices. Follow up with a few good server administrators.
Security fixes for the OS can be applied by the administrator as needed, but security fixes and bug fixes for the various components used by Mastodon itself and Mastodon itself should be done by upgrading Mastodon.
In particular, updates in units of 0.0.1, such as v3.4.1 becoming v3.4.2, are releases with minor changes that should be fixed immediately rather than in the next version. Since the changes are narrowly focused, problems are less likely to occur.